- The default TTL for EBGP peers is 1. This means that non-directly connected EBGP peers cannot be established, because the TTL will expire in transit. By issuing the ebgp-multihop [ttl] command, the TTL can be increased to support your design.
- With default EBGP sessions, a TTL of one prevents non-directly connected neighbors from forming. Additionally, IOS prevents the initiation of nondirectly connected EBGP sessions when the TTL is one (multihop is not configured), because it assumes that the TTL will expire in transit. One way of resolving this problem is to simply increase the TTL between the peers. In designs where the peers are directly connected but the peering address is a Loopback instead of the connected interface between them, the disable-connected-check neighbor option may also be used.
- Although the ebgp-multihop & disable-connected-check the difference between these features is that the disable-connected-check prevents cases in which the EBGP session between two devices is routed over another transit router 155.1.0.4 rcv UPDATE about 155.1.23.0/24 — DENIED due to: NEXTHOP is our own address;, because the TTL value remains 1.
- The BGP split-horizon rule governs the route advertisements between IBGP peers, which specifies that routes learn via IBGP are never propagated to other IBGP peers.
Note: The BGP split-horizon rule is slightly different that the split-horizon rule as in the distance vector routing protocols.
Note: Regular split-horizon rule still govern the route advertisements between EBGP peers, in which a route is not advertised back to the EBGP peer from which the route was received.
- RIB-failure by itself is not necessarily bad, but there are certain cases in which this disconnect between the BGP table and the routing table can cause traffic loops. By default, BGP routes that have RIB-failure can be advertised to other neighbors, because the command no bgp suppress-inactive is the default option under the routing process. To stop RIB-failure routes from being advertised, issue the bgp suppress-inactive command under the process.
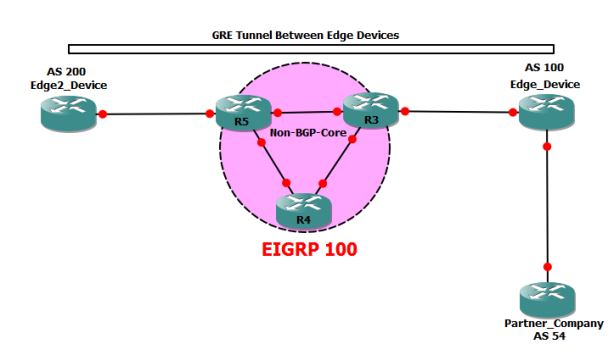
Using automatic tunneling techniques along with BGP is the core of MPLS VPNs. In this case we’ll use simple manual tunnels along with BGP to better understand possible effects. Two devices peer BGP (this could be eBGP or iBGP session) across a non-BGP-capable router cloud. This configuration means that any attempt to reach a BGP prefix across the non-BGP cloud ould result in prefix blackholing. However, if we establish a direct tunnel between the BGP peers and force all packets go across the tunnel, the non-BGP devices will never notice those packets. Thus, the “unknown” addresses will be hidden from the “core” network, only appearing at the edge routers that know about them. Notice the trick used in the solution. Although the “core” IP addresses are used for BGP peering, next-hops in BGP prefixes are modified to point to the tunnel endpoints. Alternatively, you could have peered directly off the tunnel endpoints or even used policy routing to divert packets to the tunnel interfaces:
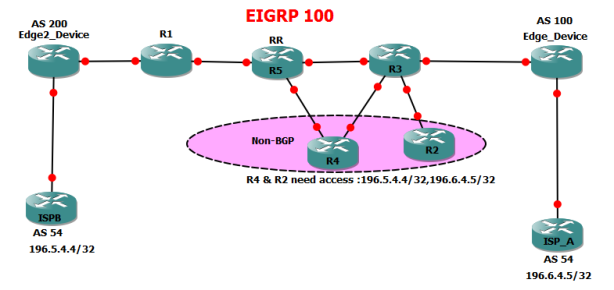
Enabling BGP on all transit devices in the AS is one way to ensure that all routers have full external routing information. This solution is scalable, because it avoids feeding large BGP tables into IGP. In some situations, you cannot enable BGP on all routers in your network. This may be the case of an enterprise network, in which only border routers peer eBGP with
the ISP. In such situations, it is common to advertise a default route from the border routers toward the rest of the network.
There could be even more complicated scenarios, such as migrating your network or gradually enabling BGP on all devices. In situations like these, you may find that iBGP peers are separated by non-BGP cloud or that non-BGP speakers need BGP
routes from the devices that learned them via iBGP (no eBGP!). So what’s wrong with redistributing iBGP prefixes into IGP? As you remember, BGP uses AS_PATH attributes to detect routing loops. When exchanging iBGP routes, AS_PATH
attributes are not prepended and thus the route loop prevention technique does not work. Because of that, feeding iBGP prefixes into an IGP may result in routing loops, because the “split-horizon” rules for BGP prefixes may be broken. To make
this situation even worse, iBGP has the AD value that makes it less preferred than any IGP. Thus, iBGP prefixes redistributed into an IGP may preempt iBGP-learned prefixes on other iBGP speakers. To prevent the above issues, iBGP-learned prefixes are not automatically redistributed into IGP when you issue the statement redistribute bgp under any IGP process on the router, only eBGP prefixes are redistributed. To make iBGP redistribution possible, you need an additional statement configured under the BGP process: bgp redistribute internal . Be very careful when enabling this feature, because you may quickly end up with routing loops, and try to avoid multiple points of iBGP to IGP redistribution.
Peer Groups
The major benefit you achieve when you specify a BGP peer group is that a BGP peer group reduces the amount of system resources (CPU and memory) necessary in an update generation. In addition, a BGP peer group also simplifies the BGP configuration. A BGP peer group reduces the load on system resources by allowing the routing table to be checked only once, and updates to be replicated to all peer group members instead of being done individually for each peer in the peer group. Based on the number of peer group members, the number of prefixes in the table, and the number of prefixes advertised, this can significantly reduce the load. It is recommended that you group together peers with identical outbound announcement policies.
router bgp 100
bgp log-neighbor-changes
neighbor 1.1.1.1 peer-group SPOKES
neighbor DMVPN_SPOKES peer-group
neighbor DMVPN_SPOKES remote-as 100
neighbor DMVPN_SPOKES route-reflector-client
























